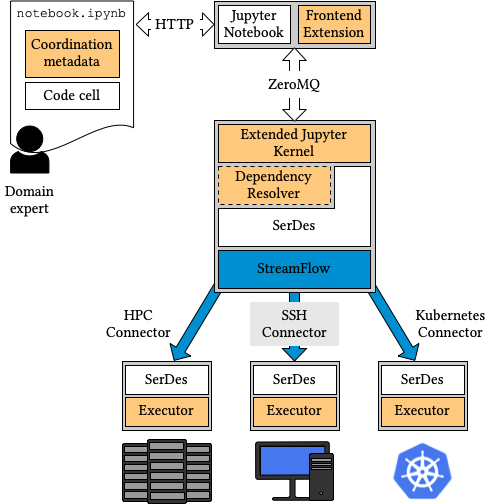
Jupyter Workflow is an extension of the IPython kernel designed to support distributed literate workflows, developed and maintained by the Alpha research group at Università di Torino (UniTO). The Jupyter Workflow kernel enables Jupyter Notebooks to describe complex workflows and to execute them in a distributed fashion on hybrid cloud/HPC infrastructures.
In particular, code cells are regarded as the nodes of a distributed workflow graph, while cell metadata are used to express data and control dependencies, parallel execution patterns (e.g. Scatter/Gather), and target execution infrastructures. Relying on cell metadata to describe workflows has several important advantages:
- It maintains a clear separation between host and coordination semantics, improving readability and maintainability of complex applications;
- It avoids technology lock-in: the same metadata format can be interpreted by different Jupyter kernels to support more languages (other than Python), specific execution architectures, or commercial software stacks;
- It smooths the learning curve with respect to stand-alone Workflow Management Systems. Users familiar with Jupyter Notebooks don’t have to learn a brand new framework to scale their experiments.
Jupyter Workflow relies on the StreamFlow Workflow Management System as its underlying runtime support. Its code is available on GitHub under the LGPLv3 license, and the related Python package is downloadable from PyPI.
If you want to cite Jupyter Workflow, please refer to this article:
I. Colonnelli, M. Aldinucci, B. Cantalupo, L. Padovani, S. Rabellino, C. Spampinato, R. Morelli, R. Di Carlo, N. Magini and C. Cavazzoni, “Distributed workflows with Jupyter”, Future Generation Computer Systems, vol. 128, pp. 282-298, 2022. doi: 10.1016/j.future.2021.10.007